建立好你的結構模型之後,就可以開始估計和檢驗你的模型了(事實上在實際研究時,通常會有兩步驟來完成結構方程模型的檢驗,第一步是檢驗你的衡量模型也就是measurement model,第二步才是檢驗你的結構模型structural model,在這邊,我們先簡單的說明結構模型的初步操作,讓大家可以很快速的先看到自己的研究結果,有關衡量模型與結構模型的說明,請見另一篇文章:PLS如何運作?)
第一步是先估計你的研究模型,操作方式非常簡單,只要照著以下的步驟操作,就可以得到結果。
1、選擇演算法
點選功能列中BT按鈕旁的倒三角型(如下圖的地方),點選後會看到下拉選單,請選擇PLS Algorithm。

2、演算法設定,點選後會看到以下畫面
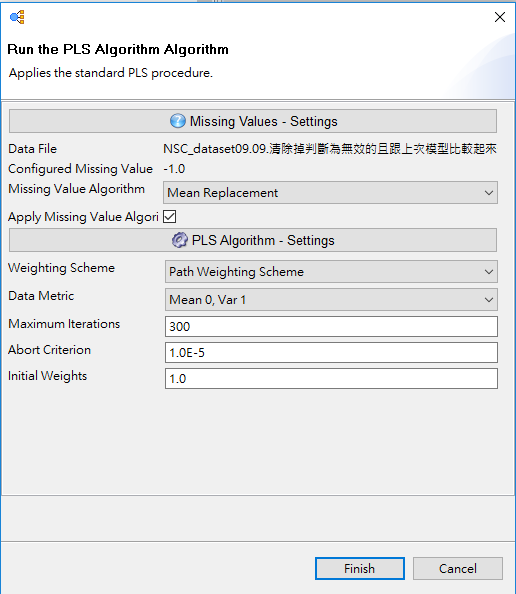
在missing values的部分,有兩種演算法可以選擇,第一種就是目前下面圖片示展現的叫做mean replacement,這種方式是運用同變數的其他樣本平均數來取代遺漏值,建議可採用這種方式,記得apply missing value algori的核取方塊要打V,另一種方式叫做case wise replacement,這種方式是當某樣本中有遺漏值的時候,就直接把整筆樣本從分析中拿掉,當然把資料拿掉就代表你會因此刪除掉非常多的資訊和樣本,當然如果你的樣本數量夠多,可以不用單心十幾個樣本被拿掉,但如果你的樣本數不多,像我的樣本是來從台灣千大公司,每一個樣本都很重要,少十個影響很大,所以我會選擇mean replacement來解決遺漏值的問題。
在PLS Algorithm - Settings的部分,Weighting scheme請選擇Path weighting scheme,至於為什麼要選這個,就又是另一個長篇大論,之後再寫文章來說明之。這邊可以引用Hair, J. F., et al. (2013). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), SAGE Publications, Inc. 的書做為參考文獻。再來data metric的部分,使用預設就行了,這邊是將資料做標準化的選項,通常會把資料轉換成標準常態分配,也就是平均數是0,標準差是1的分配,我們不用去動它。Maximum Iterations的部分一樣不用動他,這邊是指在估計參數時,最多跑300回停止,還記得PLS如何運作?裡有說的嗎?PLS是反覆的估計latent construct scores (潛在概念分數)而來的,所以這邊才會要設定最高跑幾次,因為如果收斂不了,電腦也會自動停下來。再來Abort Criterion,這邊是科學記號0.00001,跟剛才一樣,是收斂的停止條件。最後一個是initial weights,直接用預設值1就行了。選取完之後選擇finish。
3、檢視你的估計結果,從下圖可以看到Construct 內有兩個指標,一是Composite reliability,另一則是R square,這邊我們可以先看R square (Composite reliability是衡量模型要檢視的),R square並沒有一個標準,視不同領域而討論之,並非你今天得到R square值大於多少就是顯著或不顯著,也不是你的R square低於0.1就代表你的模型不好,R square只是告訴你,你的自變數能解釋依變數的程度,從0~1,0代表你的自變數完完全全跟依變數無關,1代表你的自變數可以百分之百解釋依變數。
再次檢視路徑係數,就是在Construct 間的線上的數字,這些數字代表A Construct 影響B Construct 的程度,數字愈大當然表示A Construct 影響B Construct 的程度愈大,有沒有絕對標準?一樣沒有,如同剛才說的R square一樣。

先選擇Window,裡的Preferences

選完之後會看到以下畫面,中間的Display directly就是你執行完PLS Algorithm或是其他Algorithm後,SmartPLS會直接顯示的數據,這時你可以點選右方的New按鈕

選擇後你可以看到一個對話視窗,有許多不同的數據,都可以從這邊叫出來,例如你想要在construct裡顯示出R Square,就直接在對話視窗裡選擇R Square然後按OK就行了,如果需要AVE,一樣點選AVE按OK就行了

第二步是檢驗你的結構模型的各路徑是否顯著,個步驟非常重要,前面的步驟只是告訴你路徑係數和R Square,並沒辦法告訴你,這些路徑係數是不是有所謂統計上的「顯著」,前面的只是估計值而已。所以接下來我們要使用Bootstrapping方法,來檢驗模型的各路徑是否顯著。這邊為什麼要用Bootstrapping的方法呢?那是因為PLS-SEM不像COV-SEM,PLS必需透過重複抽樣樣本集裡的樣本,藉此來估計出數個估計值,講簡單一點,Bootstrapping就是去你提供的樣本裡再抽樣出來成為一個新的樣本,這個新的樣本,就可以運用PLS Algorithm估計出我們剛才估計的所有東西(像是路徑係數),這樣Bootstrapping就得到一組全模型的估計值,接著Bootstrapping會繼續再從你的樣本裡,再抽出樣本並組成新的樣本,而這個新的樣本又可以有一組全模型的估計值,Bootstrapping重複這個步驟,可以得到N組估計值,然後再利用這N組的估計值來檢驗,看看路徑係數能不能達到顯著水準。
好吧,如果上面講的你完全不知道在講什麼,也沒關係,你只要知道,在PLS裡,你要知道路徑顯不顯著,要利用Bootstrapping方法才行!操作方法如下:
1、選擇Bootstrapping方法

2、設定Bootstrapping方法
選擇Bootstrapping後,會看到下面的對話視窗,基本上Sign Changes的部分請選擇No Sign Changes,這個選項是指當PLS在Bootstrapping的時候,抽出來的子樣本的正負號必需要和原始樣本一樣。
Cases的部分,請輸入你的樣本數,我的樣本有134個,所以就輸入134,這也是告訴Bootstrapping每次抽子樣本的時候,樣本數是134個
Samples的部分,建議5000次,這個建議值可以得到比較穩定的結果,同樣也是Hair, J. F., et al. (2013). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), SAGE Publications, Inc. 這本書藉所建議的。
設定完成後按Finish即可

3、檢視你的研究模型
Bootstrapping結束後,你應該會看到如下圖的畫面,路徑上所顯示的,是 t value, t value就告訴你,你的路徑是否顯著,那到底怎麼判斷?很簡單, t value只要大於2.57就代表你的顯著水準是1%,也就是p<0.01,就是非常顯著啦;t value大於1.96就代表顯著水準是5%,就是p<0.05,這是大家常用的標準,通常 t value要大於1.96才叫值顯著;t value大於1.65,這代表顯著水準是10%,也就是p<0.1,這是最寬鬆的標準了。

當然也不要忘記去看看你的indicators 和constructs之間loading值的顯著水準,通常所有的loading值,都必需要顯著,如下圖

也可以叫報表出來進一步的看詳細數值,方法很簡單,點選下圖的圖示即可叫出詳細報表

下圖即為詳細的報表,在Bootstrapping項目下有許多選項,你可以去看所有outer loadings值,outer loadings值的平均數、標準差、 t value等等。例如這邊點選outer loadings,你可以看到每一個Sample outer loading的估計值,這邊的一個Sample 都是Bootstrapping去抽樣你的樣本而來的一個子樣本,剛才要大家設定Bootstrapping抽樣5000次,所以在這邊的報表裡,你可以滑鼠拖曳往下看,會看到從Sample 0 一直到Sample 4999,每一個子樣本的估計值,都可以看的到喔!


老師您好, 請問一下拉smartPLS模型是不是依據研究架構的模型去拉的嗎?
回覆刪除是的!沒有先提出研究模型,基本上無從利用PLS來驗證模型。
刪除可是我smartPLS依照研究模型拉出smartPLS模型後跑出來的路徑係數t值都小於1.96 這樣是不是有問題~
刪除我的論文一直卡在這裡,尋求解救~QQ
老師您好:
回覆刪除不好意思!
我第一次接觸PLS
因為閱讀 這篇paper (企業行銷通路關係之研究-華人與西方關係觀點的整合)
作者使用的是PLS-Graph 3.0軟體。
因為問卷回收率17.17% 所以有使用T檢定 來分別檢定兩波樣本(也就是比較較早與較晚回收問卷者之間是否有差異)
我想問的是 PLS -Graph 3.0軟體 是否有檢測T檢定的功能?
我用的統計軟體都是以 SPSS 較多
看了其他論文 蠻多篇是使用SPSS+PLS
所以才有此疑問
謝謝您!
這篇論文並沒有說他是用PLS-Graph來做t檢定
刪除他的無反應偏差應該是用spss或是sas來做的,雖然在他的文中沒有指明
老師 謝謝您!
刪除我也是這樣認為 應該是用spss 或是 sas
但因為我沒用過PLS的軟體 ( 所以不知道是否有T檢定的功能 )
我問同學 同學也不知道 -因為大家都沒用過這軟體
上網查資料 一開始都是查到PLS+SPSS
後來又查PLS的操作方式... 又好像有t檢定的功能
但不知道是否只是有t值呈現 但卻無法像SPSS 或 SAS 做配對t 、獨立樣本t檢定....甚至是文章中說的無反應偏差
我也不太好意思 再寫信問原作者>"<
看paper就是會有一些盲點
尤其是自己不熟的領域
非常謝謝您的回覆!
您好,老師想請教您,我照個步驟做,有些t值達到8以上,甚至有個路徑達到T=17....雖然這樣代表顯著性很高,但我想是不是隱藏著一些問題?謝謝!
回覆刪除有,很可能存在共同方法變異common method variance問題
刪除作者已經移除這則留言。
刪除謝謝老師回覆,但我目前是碩士新手,不太了解這個名詞意思。剛剛上網查,好像是說問題的同樣程度太高。但現在有點不知道怎麼補救,可以的話煩請略微指點,謝謝!(補充:信度效度目前測試都是無問題的)
回覆刪除老師您好:
回覆刪除不好意思! 我對於PLS目前尚在摸索的階段,看到您的文章覺得非常有幫助,在此想請問您一個小問題,就是PLS在跑資料分析的時候可以像刪除遺漏值那樣,自動幫我們篩選掉遺漏值嗎?
謝謝老師!
Portable SmartPLS 3.2.8 Full Version
回覆刪除便携式SmartPLS 3.2.8完整版
SmartPLS 3.2.8完整版是具有图形用户界面的软件基于多样性的结构方程模型(SEM)使用最小的部分路径建模方法(PLS)
(SmartPLS is a software with graphical user interface for
variance-based structural equation modeling (SEM)
using the partial least squares (PLS) path modeling method)
链接下载SmartPLS 3.2.8完整版
http://updatetribun.org/SmartPLS
下载和下载指南
https://s.id/HowDownload
https://s.id/HowDownload
#olahdatasemarang
老師您好,不好意思打擾,想請教一下如果我是做比較偏向心理相關的研究,主要探討變數之間的相關性,但因應學校要求還是有畫出model,請問還需要以pls做分析嗎?
回覆刪除小弟是已經跑過了但由於題向factor loading的數值實在有些奇怪,因此想說來請教
作者已經移除這則留言。
刪除